

Why the rise of AI-assisted development makes precise specifications more important, not less.
There is a conversation happening in software and testing teams right now that goes roughly like this: “We have Claude now. We can just describe what we want in plain English and get code back. Do we still need all the formal tooling? Or even testers or developers to run it all?”
These are fair questions. But they rest on a misunderstanding of what an LLM actually does, and once you see it clearly the answers flip completely.
Everything Is a Compiler
Let’s start with a provocation: every tool in the software development chain is, at its core, a compiler. That is, it takes a specification written in one language and transforms it into something executable in another.
A traditional compiler takes Java or C, itself a specification of intended behaviour, and maps it to machine code or bytecode. A model-based development tool takes a formal model expressed in UML, SysML, or a domain-specific test specification language, and generates test scripts, test data, or production code in Java, Playwright, JUnit, or similar. And an LLM takes a specification written in natural language (a prompt, a requirement, or a user story) and maps it to code, tests, or structured data.
Same pattern, three different notations for the input.
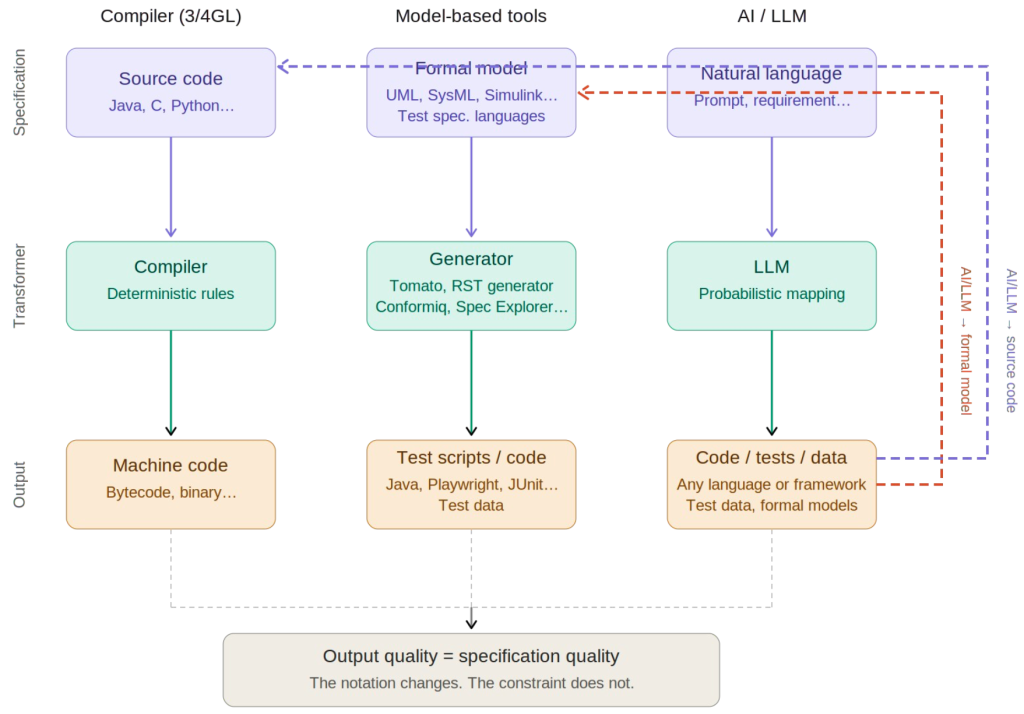
Figure 1: Three transformer columns (Compiler, Generator, and LLM), each taking a specification and
producing output. The dashed arrows show how LLM output can feed back into the stack as source code or as a formal model for downstream tools. Note the dashed arrows: the LLM column doesn’t stand apart; its outputs become inputs to the tools on the left.
The critical insight is this: in all three cases, the quality of the output is bounded by the quality of the specification. The transformer in the middle, whether it is a deterministic compiler, a rule-based generator, or a probabilistic neural network, cannot manufacture correctness that was never in the input. It can only faithfully render what was expressed, and fill in the gaps with guesses.
This applies as much to LLMs as to any other tool in the stack. The notation changes; the constraint does not.
What Changes With LLMs, and What Doesn’t
LLMs do introduce something genuinely new: a dramatic reduction in the cost of expressing a specification. Natural language is something every engineer, product manager, and domain expert already speaks. You do not need to learn UML or a formal DSL to write a prompt. The feedback loop between “I have an idea” and “I have running code” has collapsed from days to minutes.
That is real and important. But it is a change in notation cost, not a change in the fundamental problem. The specification problem of figuring out precisely and completely what you actually want has not gone away. It has merely moved upstream.
There is also a subtler difference, and it is the dangerous one. A compiler and a model-based generator fail loudly on ambiguity. If your model is underspecified or internally inconsistent, the tool tells you. An LLM does the opposite: it fills ambiguity silently with a plausible-sounding answer. You get output that looks correct, compiles, and passes casual review, but embeds an assumption you never made. The specification hole becomes invisible until something breaks in production.
This is not an argument against LLMs. It is an argument for understanding what kind of tool they are.
Not Competing Layers, but Complementary Ones
The practical implication follows naturally: LLMs and model-based tools are not alternatives to each other. They are layers in a pipeline, and LLMs can feed into model-based tools just as naturally as they can replace manual coding.
Consider a specification-driven test data generator that takes a formal model as input. An LLM can help engineers translate messy, incomplete natural language requirements into a well-structured model. The LLM brings speed and accessibility to the specification authoring step. The model-based tool then takes that model and performs the exhaustive, deterministic transformation that produces reliable test data. That is exactly what we do in our AI-assisted, model-based testing tool, Tomato.
This same pattern works across the whole stack. An LLM can generate source code that feeds a compiler. It can generate a formal model that feeds a test data generator. It can generate a test specification that feeds a scripting tool. In each case, the LLM is acting as a specification translator, bridging from human intent to a more structured form that a downstream tool can process reliably.
The pipeline is not: LLM replaces everything before it. The pipeline is: LLM as a new, accessible front-end to a stack of tools that each do what they do best.
The Real Shift
What AI-assisted development actually changes is not which tools you need. It is where the hard thinking happens.
For decades, the bottleneck in software and test development has nominally been coding: the mechanical act of translating a known requirement into a working implementation. That bottleneck is largely gone. An LLM handles the mechanical translation with remarkable fluency.
What remains, now more exposed than ever, is requirements engineering. Thinking clearly about what you want. Specifying it precisely enough to be unambiguous. Identifying the edge cases before the generator does it for you, incorrectly, silently, at scale.
Model-based tools have always lived at this layer. They have always demanded a well-formed specification as their input, and rewarded you with reliable, comprehensive output when you provided one. A Python program illustrates the same principle: it is a precise specification of intended behaviour, expressed in a language a machine can execute without guessing. That discipline is not a limitation of older tooling. It is the entire point. What LLMs have changed is not the discipline itself, but where the specification journey begins. Natural language is now the starting layer, before any formal structure is imposed.
In a world where LLMs make the coding step trivially fast, investing in specification quality is not just good practice. It is the only remaining lever that actually moves the needle on output quality.
What About the People?
The companion question, whether we still need dedicated testers and developers, follows exactly the same logic. Let’s take testers as an example. LLMs have made some of the mechanical work in testing cheaper and faster. But testing is a discipline in its own right, with its own methods, coverage models, risk frameworks, and a substantial body of knowledge built around verification and validation. It is not merely checking whether something appears to work.
The crucial distinction is between verification and independent verification. When a developer, whether human or AI-based, tests their own code, they are, in practice, verifying their own understanding of the requirements and their own implementation assumptions. An independent tester brings a structurally different perspective: are the requirements correctly understood? Is the solution correct not just in isolation, but in interaction with other systems, under load, at failure boundaries, in edge cases, and under real usage conditions? These are different questions, and they require a different vantage point to ask well.
Domain experts and end users are essential contributors to validation; nobody else knows how the system should actually behave in the context of real work. But they typically lack the methodological toolkit to design test coverage, reason systematically about integration failure modes, or build test strategies that surface what is not obviously broken. Their contribution is most valuable when it sits inside a structured test effort led by experienced specialists, not when it replaces one.
Good test automation sharpens this point further. Building sustainable automated test suites is not just scripting: it requires architectural decisions about modularity, maintainability, and the cost-benefit of what to automate at which level. Poorly designed automation produces fragile, expensive, and misleading results. Well-designed automation reduces regression risk, accelerates feedback, and lowers the long-term cost of change. That kind of work requires people who understand both software development and testing at depth.
What AI changes is not which skills matter; it is where skilled people spend their time.
Back to blog